
seaking110 님의 블로그
plus 주차 개인 과제 본문
Plus 주차 개인 과제를 진행하며 배운 점 정리
Level 1
3. 코드 개선 퀴즈 - JPA의 이해
- 할 일 검색 시 weather 조건으로도 검색할 수 있어야해요.
- weather 조건은 있을 수도 있고, 없을 수도 있어요!
- 할 일 검색 시 수정일 기준으로 기간 검색이 가능해야해요.
- 기간의 시작과 끝 조건은 있을 수도 있고, 없을 수도 있어요!
- 조건은 날씨와 수정일 기준의 기간 검색으로 필터가 추가되는 방식
@GetMapping("/todos")
public ResponseEntity<Page<TodoResponse>> getTodos(
@RequestParam(defaultValue = "1") int page,
@RequestParam(defaultValue = "10") int size,
@RequestParam(required = false) String weather,
@RequestParam(required = false) String startDate,
@RequestParam(required = false) String endDate
) {- required = false를 추가하여 없어도 되는 값으로 처리
- 없을 수도 있기 때문에 String으로 받기로 결정
- null 체크를 컨트롤러 서비스 레파지토리 중 레파지토리에서 하기로 결정
- Where 절에 null이 아니면 필터를 하나씩 넣어주려고 했는데 여기서 방식 고민
- IS NULL OR 이라는 방식을 배움
@Query(
"select u "+
" from user u " +
" where (:searchId is null or u.id = :searchId) "+
)- JPQL에서 쓸 수 있는 null 체크 및 null이 아닐 때 검색 처리 방식을 배움
Level 2
6. JPA Cascade
- Cascade는 @OneToMany 또는 @OneToOne도 가능
- 사용 조건
- 대상 엔티티로의 영속성 전이는 현재 엔티티에서만 전이 되어야한다.
- 양쪽 엔티티의 라이프 사이클이 동일하거나 비슷해야한다.
- 옵션 종류
- ALL : 전체 상태 전이
- PERSIST : 저장 상태 전이
- REMOVE : 삭제 상태 전이
- MERGE : 업데이트 상태 전이
- REFERESH : 갱신 상태 전이
- DETACH : 비영속성 상태 전이
- 따라서 저장을 같이하려면 PERSIST 저장 상태를 전이해야함
차이점
- Cascade.REMOVE는 부모를 삭제하면 자식도 삭제
- orphanRemoval =true는 부모의 리스트에서 자식 요소를 삭제하면 해당 자식 엔티티가 삭제
영속성 전이 최강 조합 :Cascade.REMOVE + orphanRemoval =true
8. QueryDSL
QueryDSL은 사용을 정말 오랜만에 해보는 것 같다. 학교 다닐때 조금 써봤나? 기억도 안나니까 처음 배운다는 마음으로!
- build.gradle에 설정 추가
// queryDSL
implementation 'com.querydsl:querydsl-jpa:5.0.0:jakarta'
annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jakarta"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"- JPAConfiguration을 설정
@Configuration
public class JPAConfiguration {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}- 해당 레파지토리의 쿼리DSL용 레파지토리 인터페이스 생성
public interface CommentRepositoryQuery {
List<Comment> findByTodoIdWithUser(@Param("todoId") Long todoId);
}
- 인터페이스에 대한 구현체 생성
@RequiredArgsConstructor
@Repository
public class CommentRepositoryQueryImpl implements CommentRepositoryQuery{
private final JPAQueryFactory jpaQueryFactory;
@Override
public List<Comment> findByTodoIdWithUser(Long todoId) {
QComment comment = QComment.comment;
QUser user = QUser.user;
return jpaQueryFactory
.selectFrom(comment)
.join(comment.user, user).fetchJoin()
.where(comment.todo.id.eq(todoId))
.fetch();
}
}
- 위와 같이 생성하면 됨!
- 의문점
- 새로 만든 레파지토리의 연결을 서비스로 바로하는게 맞을까? 기존 레파지토리랑 연결을 하는게 맞을까?
9. Spring Security
- 드디어 기다리고 기다리던 Spring Security를 사용해본다!
- 사전 설정 (build.gradle) 추가
//== 스프링 시큐리티 ==//
implementation 'org.springframework.boot:spring-boot-starter-security'
testImplementation 'org.springframework.security:spring-security-test'
- JwtAuthenticationFilter 생성 (기존 필터를 대체)
더보기
doFilterInternal 메서드 : 헤더의 Authorization에서 token을 가져와 정보 검증
setAuthentication 메서드 : 정보를 통해 AuthUser를 생성하고 SecurityContext에 등록
@Slf4j
@Component
@RequiredArgsConstructor
public class JwtAuthenticationFilter extends OncePerRequestFilter {
private final JwtUtil jwtUtil;
@Override
protected void doFilterInternal(HttpServletRequest request, @NonNull HttpServletResponse response, @NonNull FilterChain filterChain) throws ServletException, IOException {
String authorizationHeader = request.getHeader("Authorization");
if (authorizationHeader != null && authorizationHeader.startsWith("Bearer ")) {
String jwt = jwtUtil.substringToken(authorizationHeader);
try {
Claims claims = jwtUtil.extractClaims(jwt);
if (SecurityContextHolder.getContext().getAuthentication() == null) {
setAuthentication(claims);
}
} catch (SecurityException | MalformedJwtException e) {
log.error("Invalid JWT signature, 유효하지 않는 JWT 서명 입니다.", e);
response.sendError(HttpServletResponse.SC_UNAUTHORIZED, "유효하지 않는 JWT 서명입니다.");
} catch (ExpiredJwtException e) {
log.error("Expired JWT token, 만료된 JWT token 입니다.", e);
response.sendError(HttpServletResponse.SC_UNAUTHORIZED, "만료된 JWT 토큰입니다.");
} catch (UnsupportedJwtException e) {
log.error("Unsupported JWT token, 지원되지 않는 JWT 토큰 입니다.", e);
response.sendError(HttpServletResponse.SC_BAD_REQUEST, "지원되지 않는 JWT 토큰입니다.");
} catch (Exception e) {
log.error("Internal server error", e);
response.sendError(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
}
}
filterChain.doFilter(request, response);
}
private void setAuthentication(Claims claims) {
Long userId = Long.valueOf(claims.getSubject());
String email = claims.get("email", String.class);
UserRole userRole = UserRole.of(claims.get("userRole", String.class));
log.error(userRole.name());
String nickName = claims.get("nickName", String.class);
AuthUser authUser = new AuthUser(userId, email, userRole, nickName);
JwtAuthenticationToken authenticationToken = new JwtAuthenticationToken(authUser);
SecurityContextHolder.getContext().setAuthentication(authenticationToken);
}
}- JWTAuthenticationToken 생성 (기존의 AuthUserArgumentResolver 대체)
더보기
public class JwtAuthenticationToken extends AbstractAuthenticationToken {
private final AuthUser authUser;
public JwtAuthenticationToken(AuthUser authUser) {
super(authUser.getAuthorities());
this.authUser = authUser;
setAuthenticated(true);
}
@Override
public Object getCredentials() {
return null;
}
@Override
public Object getPrincipal() {
return authUser;
}
}- SecurityConfig (기존의 FilterConfig 대체)
더보기
public class SecurityConfig {
private final JwtAuthenticationFilter jwtAuthenticationFilter;
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity httpSecurity) throws Exception {
return httpSecurity
.csrf(AbstractHttpConfigurer::disable)
.sessionManagement(session -> session.sessionCreationPolicy(SessionCreationPolicy.STATELESS))
.addFilterBefore(jwtAuthenticationFilter, SecurityContextHolderAwareRequestFilter.class)
.formLogin(AbstractHttpConfigurer::disable)
.anonymous(AbstractHttpConfigurer::disable)
.httpBasic(AbstractHttpConfigurer::disable)
.logout(AbstractHttpConfigurer::disable)
.rememberMe(AbstractHttpConfigurer::disable)
.authorizeHttpRequests(auth -> auth
.requestMatchers(request -> request.getRequestURI().startsWith("/auth")).permitAll()
.requestMatchers(request -> request.getRequestURI().startsWith("/admin")).hasAuthority(UserRole.Authority.ADMIN)
.anyRequest().authenticated()
)
.build();
}
}- 추가적으로 PasswordEncoder는 이제는 Spring Security에서 제공
- @Auth 역시 Spring Security에서 제공하는 @AuthenticationPrincipal 사용
Level 3
10. QueryDSL 을 사용하여 검색 기능 만들기
- 이전 QueryDSL과 다른 점은 Page를 한다!
- 조건 중 null이 아닐때만 조건을 걸어줘야한다!
- page 처리
List<Todo> todos = jpaQueryFactory
.selectFrom(todo)
.leftJoin(todo.user, user).fetchJoin()
.leftJoin(todo.comments, comment).fetchJoin()
.where(builder)
.orderBy(todo.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
List<TodoSearchResponse> list = new ArrayList<>();
for (Todo t : todos) {
list.add(new TodoSearchResponse(
t.getId(),
t.getTitle(),
t.getManagers().size(),
t.getComments().size()
));
}
Long total = jpaQueryFactory
.select(todo.count())
.from(todo)
.where(builder)
.fetchOne();
long totalCount = (total != null) ? total : 0L;
return new PageImpl<>(list, pageable, totalCount);- 전체 갯수를 구하기 위해 total 개수를 구해야한다!
- 또한 offset과 limit를 잘 이용하여 페이징 처리를 해준다!
- null 조건 처리
BooleanBuilder builder = new BooleanBuilder();
if (title != null) {
builder.and(todo.title.eq(title));
}
if (start != null) {
builder.and(todo.createdAt.after(start));
}
if (end != null) {
builder.and(todo.createdAt.before(end));
}
if (nickName != null) {
builder.and(todo.user.nickName.eq(nickName));
}- builder를 만들어서 where 절에 null이 아니면 추가 가능하게 처리
- where 절에선 builder를 넣어주면 처리 끝
.where(builder)
11. Transaction 심화
- 핵심은 Transation의 Propagation 설정에 따른 변경 점을 알자!
- 매니저로 등록하는 과정에서 Log를 저장하는 서비스를 호출할때! 매니저 등록에 실패해도 로그는 저장되어야한다!
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void saveLog(String name, String title) {
logRepository.save(new Log(name, title));
}- 이런식으로 Transactional에 propagation의 값을 REQUIRES_NEW로 설정하면 트랜잭션을 기존을 쓰는 것이 아닌 새로운 트랜잭션을 만들어서 진행! 따라서 매니저 쪽에서 예외가 발생해도 다른 트랜잭션을 사용하여 로깅은 저장!
12. AWS 활용
- AWS로 배포 방법
- EC2
- beanstalk
- EC2를 활용하여 진행
- 먼저 서버 접속 및 live 상태를 확인할 코드 생성
@RestController
public class HealthCareController {
@GetMapping("/check")
public ResponseEntity<String> healthCheck() {
return ResponseEntity.ok("Ok");
}
}- 빌드 전 application.yml을 aws의 rds에 맞게 datasource 수정
datasource:
url: jdbc:mysql://(rds 엔드포인트):3306/(db 스키마 이름)
username: 이름
password: 비번
driver-class-name: com.mysql.cj.jdbc.Driver- 빌드 하여 .jar 파일 생성
- ./gradlew build로 생성
- 그냥 프로젝트 build 하니까 snapshot파일이 안생김 (왜?)
- 또한 gradle-wrapper properties가 있어야 빌드 가능
- 만든 jar 파일을 aws의 인스턴스의 우분투 안으로 옮기기 위해 파일질라 사용
- aws의 key파일을 사용하여 간단하게 성공!
- 그전에 key파일의 권한을 변경해야함!!
- 이동 후 java -jar expert-0.0.1-SNAPSHOT.jar로 실행
- 그전에 java 다운로드 필요
- 그러고 인스턴스에 배정된 IP로 postman을 작동 시키면 작동 완료!!

AWS 배포 순서 정리
- EC2 인스턴스 생성 및 보안 그룹 설정 (외부나 특정 IP에서 접근 허용)
- RDS 생성 및 EC2로 접근을 허용하기 위해 인바운드 보안 설정
- EC2 인스턴스 안의 우분투에 JDK 설치
- 파일질라를 이용하여 우분투 내부로 파일 전송
- 실행
- PostMan으로 테스트


- 배포가 개인적으로 여태까지 배운 것 중에 제일 어려운듯하다 beanstalk로도 한번 해봤는데 훨씬 쉽긴한데 알 수 없는 문제가 발생해서 포기했다! 나중에 다시 시도해보자!
- 정말 수도 없이 많은 오류가 발생해서 별 짓 다해봤다 그래도 이번 기회에 배포를 제대로 배운것 같아서 좋다!
13. 대용량 데이터 처리
- 저번 과제에서 대용량의 데이터를 넣으려고 프로시져를 이용해서 데이터를 넣었는데 이번에는 테스트 코드로 유저 데이터를 100만건 생성하는게 조건이다!
- 알아본 결과 FAKER를 사용하면 된다고 봤다! 하지만 Build가 되지 않는다!!

- 하지만 빌드가 되지 않았다!
- 이유를 찾아보니 faker는 오래된 방식이고 따라서 버전을 강제로 다운그레이드 해야한다는 것을 알아냈다!
implementation 'com.github.javafaker:javafaker:1.0.2'
implementation 'org.yaml:snakeyaml:1.23'
- 하지만 오래된 방식이고 다른 것을 다운그레이드 해서 쓰는 것보다는 다른 방식이 있지 않을까 생각하여 추가적인 방법을 찾아보니
- datafaker라는 사용법은 비슷하고 더욱 안정적인 방법이 있다고 하여 사용하기로 결정!
// faker
implementation 'net.datafaker:datafaker:2.0.2'- 그리고 nickname으로 검색을 하는 코드 작성
// controller
@GetMapping("/users")
public ResponseEntity<List<UserSearchResponse>> getUsers(@RequestParam String nickName) {
return ResponseEntity.ok(userService.getUsers(nickName));
}
// service
public List<UserSearchResponse> getUsers(String nickName) {
if (nickName.isEmpty() || nickName.isBlank()) {
throw new InvalidRequestException("닉네임을 입력해주세요");
}
List<User> userList = userRepository.findByNickName(nickName);
return userList.stream().map(user -> new UserSearchResponse(user.getId(), user.getEmail(), user.getNickName())).collect(Collectors.toList());
}
- 그 후 100만개를 생성하는 테스트 코드 작성
- 이어서 성공하는 테스트 코드를 짜고 해당 테스트를 호출하는 식으로 진행
- 그보다 @BeforeEach나 @BeforeAll을 사용하면 더욱 편하게 진행이 될거 같아 해당 방식으로 변경
@BeforeEach
void setUp() {
// 100만 개의 더미 데이터 생성
userList = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
// 랜덤 이메일
String email = faker.internet()
.emailAddress();
// // 랜덤 비밀번호
// String password = faker.internet()
// .password(8, 16, true, true, true);
// 랜덤 닉네임
String nickname = faker.funnyName().name();
User user = new User(email,"1234", UserRole.ROLE_USER, nickname);
userList.add(user);
}
existingNickName = userList.get(faker.random().nextInt(0, userList.size() - 1)).getNickName();
}
@Test
void getUsers_Success() {
// given
List<User> expectedUsers = userList.stream()
.filter(user -> user.getNickName().equals(existingNickName))
.collect(Collectors.toList());
StopWatch stopWatch = new StopWatch();
stopWatch.start();
when(userRepository.findByNickName(existingNickName)).thenReturn(expectedUsers);
// when
List<UserSearchResponse> result = userService.getUsers(existingNickName);
stopWatch.stop();
// then
assertNotNull(result);
System.out.println(stopWatch.prettyPrint());
}- 또한 stopWatch 기능을 사용하여 성능을 확인해볼 계획
- 현재 코드에서 3번 돌려본 결과
- 평균적으로 0.026초 정도로 계산되었다.
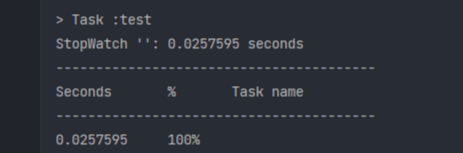


- 이제 성능을 개선 시켜 보자!
- 성능을 개선 시키는데는 3가지? 정도가 생각이 났다
- 코드 개선
- 쿼리 개선
- 인덱스 생성
- 코드 개선
- 코드를 개선할 것에는 뭐가 있을까 생각해본 결과 stream을 쓰면 성능적으로는 안좋다? 라고 들었던 기억이 생각나서 stream을 삭제 해보도록 결정
- for문을 통해 생성
List<UserSearchResponse> responseList = new ArrayList<>();
for (User user : userList) {
responseList.add(new UserSearchResponse(user.getId(), user.getEmail(), user.getNickName()));
}
return responseList;- 다시 성능 체크



- 오! 아주아주 조금이지만 성능이 개선되었다 평균적으로 0.022초
- 다음으로 쿼리를 개선 시켜 보자!
- JPQL 과 QueryDSL 중 고민을 하던 중
- 이제는 JPQL에서 원하는 필드만을 뽑아 쓰는 방식을 사용하지 않는다고...
- 대신 JPA Projections을 사용한다라는 정보!
- 한번 사용해보록 하자!
- Dto를 인터페이스로 변경!
public interface UserSearchResponse {
Long getId();
String getEmail();
String getNickName();
}
- 레파지토리의 반환 값을 dto로 변경
List<UserSearchResponse> findByNickName(String nickName);- 반환 값이 dto로 변경 되어 그냥 반환
- 자연스럽게 for문이나 stream은 삭제
public List<UserSearchResponse> getUsers(String nickName) {
if (nickName.isEmpty() || nickName.isBlank()) {
throw new InvalidRequestException("닉네임을 입력해주세요");
}
return userRepository.findByNickName(nickName);
}- 이제 성능을 확인해보자



- 정말 미미하지만 0.02초 까지 성능이 개선되었다!
- 마지막 성능 개선 방법인 인덱스를 사용해보자!
- 아무 생각 없이 MySQL에 인덱스를 만들고 성능을 체크했더니 아무 변화가 없었다!
- 맞다! 테스트 코드는 DB를 H2를 쓰고 있으니 H2에다가 인덱스를 만들어줘야한다!
- H2에서 인덱스를 만드는 방법은 엔티티에 인덱스를 생성해주는 방법이 있었다.
@Table(name = "users", indexes = { @Index(name = "idx_nick_name", columnList = "nick_name")})- 하지만 성능적으로 차이가 아예 없다!
- h2에서 인덱스가 생성이 되지 않은건지 원래 인덱스가 있었던건지는 잘 모르겠다!
- 나중에 프로시져를 활용해서 mysql에 직접 데이터를 넣어보고 진행하여 확인해보도록 하자!
| 1회 | 2회 | 3회 | 평균 | |
| 기존 코드 | 0.026초 | 0.024초 | 0.028초 | 0.026초 |
| 코드 개선(stream 삭제) | 0.023초 | 0.022초 | 0.023초 | 0.023초 |
| 쿼리 개선 (JPA Projections) | 0.02초 | 0.02초 | 0.02초 | 0.02초 |
'Today I Learned' 카테고리의 다른 글
| AWS 특강 (0) | 2025.03.24 |
|---|---|
| plus 주차 트러블 슈팅 (0) | 2025.03.21 |
| AWS 시작하기! (0) | 2025.03.20 |
| Spring Security 와 WAS (0) | 2025.03.12 |
| Spring Security (0) | 2025.03.12 |
'Today I Learned' Related Articles
more

